Introduction
In this blog post, we discuss Docwire's adaptation of the PIMPL idiom, which has greatly helped us reduce not only compile-time dependencies but also maintain a healthy encapsulation level over implementation details. However, to lay bare the conceptual thinking behind this adaptation, we do not want to present the actual implementation of the PIMPL idiom directly; rather, we want the reader to understand the intuition behind it. Once we have covered the necessary ground, the strange-looking code will automatically make sense. So bear with us!
Addressing Dependencies in C++
Managing dependencies well has always been the philosophy of C++ design to ensure solid code. And the reason being C++’s greatest strength is that it supports two powerful methods of abstraction: object-oriented programming and generic programming, which help manage dependencies and complexities (Sutter, 1999, #). Usually, when we discuss dependencies concerning code, we often talk about run-time dependencies like class interaction, but here, our concern lies with managing compile-time dependencies.
Have a look at the minimalistic code example below:
class D {
public:
int num = 10;
};
#include "d.h"
#include <memory>
class Y {
public:
explicit Y(const D &d);
~Y();
void someImpl();
private:
D d_;
};
#include "y.h"
#include "iostream"
Y::Y(const D &d) : d_(d) {}
Y::~Y() = default;
void Y::someImpl() { std::cout << d_.num << std::endl; }
------------------------------
The file to notice here is y.h since this is the file that will be included in some main.cpp. Usually, programmers #include many more headers than necessary, which unfortunately degrades build times, especially when a popular header file includes too many other headers. Ours above is a simplistic one, yet enough to convey the message. Can we somehow remove any header from this file while still having our code compile and run successfully?
When we review the code closely, we see that a certain D appears as a private data member of our class Y as well as a parameter inside its constructor. In C++, we can easily encapsulate the private parts of a class from unauthorized access; however, it requires a bit more work to encapsulate dependencies on a class's private parts, due to the header approach borrowed from the C-Language. A genuine argument may be raised that a client code does not need to care about access to private members of a class; however, since the privates are visible in the header, the client code does have to depend upon any types they mention.
Classic PIMPL approach
To better insulate clients from a class's private implementation details, a special form of handle/body idiom (Coplien, 1991, #), often called the PIMPL idiom, is used. A PIMPL is a pointer pointing to an undefined class, which will be used to hide the private members (and later implementation details) of the current class. The PIMPL idiom leverages C++'s ability to allow pointers to incomplete types and forward declare an entity, such as a type, variable, constant, or function for which a complete definition is yet to be provided. It just allows the compiler to validate the code and tidy up loose ends to produce a neat-looking object file.
`
#include <memory>
class D;
class Y {
public:
explicit Y(const D &d);
~Y();
void someImpl();
private:
struct YImpl;
std::unique_ptr<YImpl> yPiml_;
};
`
See how thed.h header has been replaced with a forward declaration since it is being mentioned as a parameter in the constructor. But, more importantly, pay attention to the forward declaration of the type YImpl; the implementation of it is yet to be seen, and a pointer yPiml_ to hold its object. Now, the private details go to our implementation file y.cpp, which is not visible to the client’s eyes.
`
#include "y.h"
#include "d.h"
#include <iostream>
#include <memory>
struct Y::YImpl {
D d_;
YImpl(const D &d) : d_(d) {}
};
Y::Y(const D &d) : yPiml_(std::make_unique<YImpl>(d)) {}
Y::~Y() = default;
void Y::someImpl() { std::cout << yPiml_->d_.num << std::endl; }`
🔍Consider the memory layout of our class Y. Since it depends only on the data members whose sizes are known, in this case, we just have one data member yPiml_. Hence, on a 64-bit system, the size of class Y will be 8 bytes, and on a 32-bit system, its size will be 4 bytes. Notice, now the implementation of the class can be changed, i.e., private members can be freely added or removed, and it would not require compiling client code. The binary layout of our class is now stable. We can take one step further and even add some other implementation details inside.
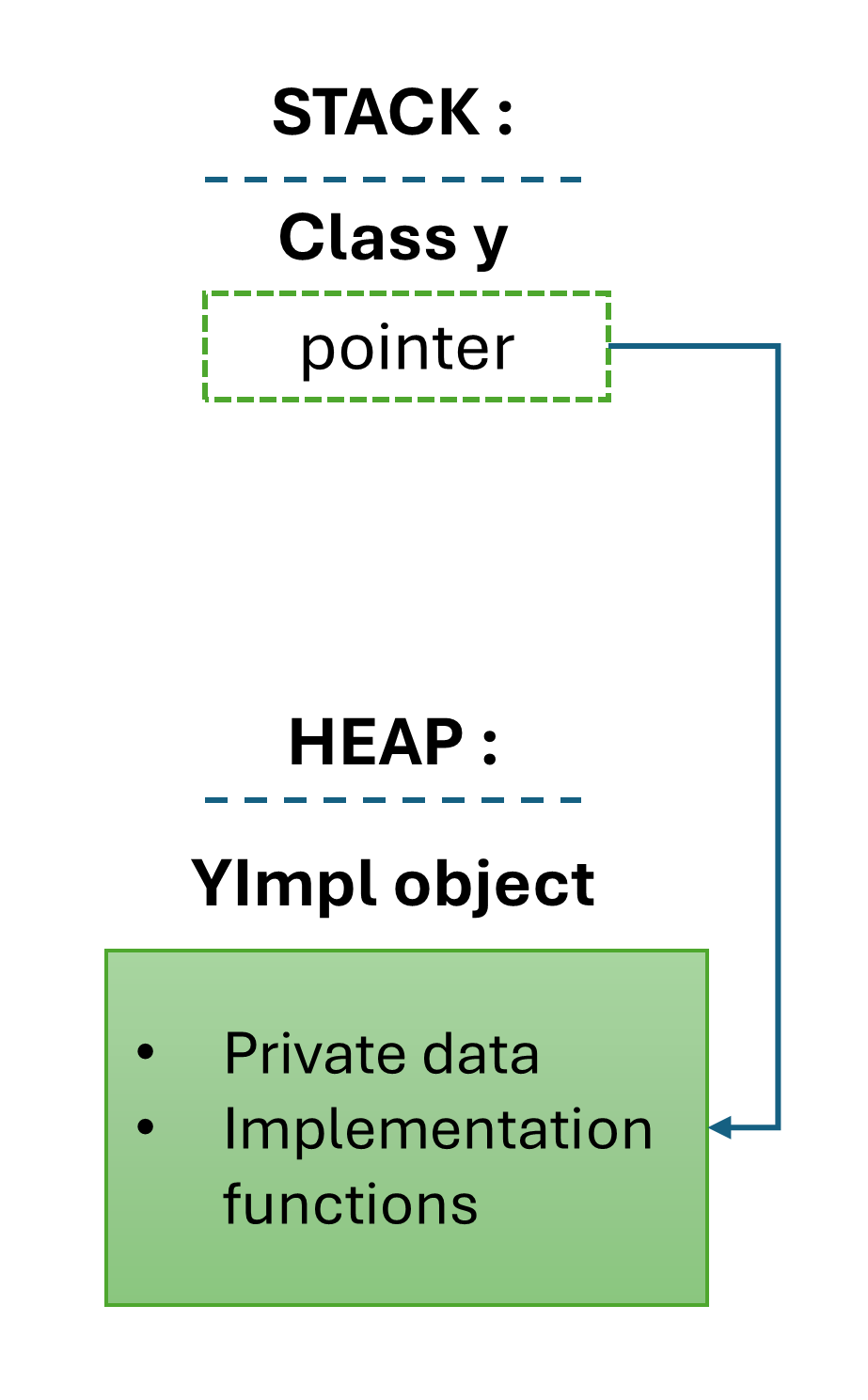
Now, if we modify our class and add some operation implementations as well inside our YImpl, ABI remains stable.
Cost of the PIMPL idiom
⚠️However, with every design choice is associated a trade-off, and it would be naive not to consider the cost of the PIMPL idiom in our design. Now, every class Y object dynamically allocates its YImpl object on the heap, and this now requires every construction and deconstruction to allocate/deallocate memory. Moreover, each access to a hidden member requires at least one extra indirection, which makes the case for a potential cache miss.
Heap allocation is an expensive operation. Not only does it require subtleties such as free arena lookup and memory management, but it also affects locality. Modern CPUs never directly read RAM but load cache lines first. Stack allocations are naturally contagious, but heap allocators scatter memory as it serves as per availability basis. Since the OS does not give memory per allocation, and memory comes in large chunks, the malloc() operating internally does not allocate sequentially per object, but it subdivides large regions and keeps a track of used/free blocks and tries to reuse memory whenever possible.
In our case, since we are using a pointer to some random heap address, the class objects are usually in different cache lines, and a potential miss becomes more likely. Moreover, the CPU predicts patterns for the hardware prefetcher; however, heap addresses are random, and hence, that also fails.
Say, our modified class now looks like:
#include <memory>
class D;
class Y {
public:
explicit Y(const D &d);
~Y();
void someImpl();
virtual void notify();
void run();
private:
struct YImpl;
std::unique_ptr<YImpl> yPiml_;
};
#include <memory>
struct Y::YImpl {
D d_;
YImpl(const D &d) : d_(d) {}
void do_run(Y *owner) {
owner->notify();
}
};
Y::Y(const D &d) : yPiml_(std::make_unique<YImpl>(d)) {}
Y::~Y() = default;
void Y::someImpl() { std::cout << yPiml_->d_.num << std::endl; }
void Y::run() {
yPiml_->do_run(this);
}
void Y::notify() {
👀Look closely, and you will find that our class Y has now been made a polymorphic base class. Earlier, the compiler was aware of its definite behavior, but now it acts as an extensible interface. Now, if there is a derived class from our class Y, the compiler does not know whether the actual object is of type Y or its derived type. The call to the virtual function will be decided at run time.
But more importantly, the implementation YImpl does not depend on derived interface types. It is delegating the policy back to the interface Y via owner->notify(). It is still loosely coupled and can handle private implementation details with ease. So, how does the memory layout look for class Y now, and what happens when run is executed?
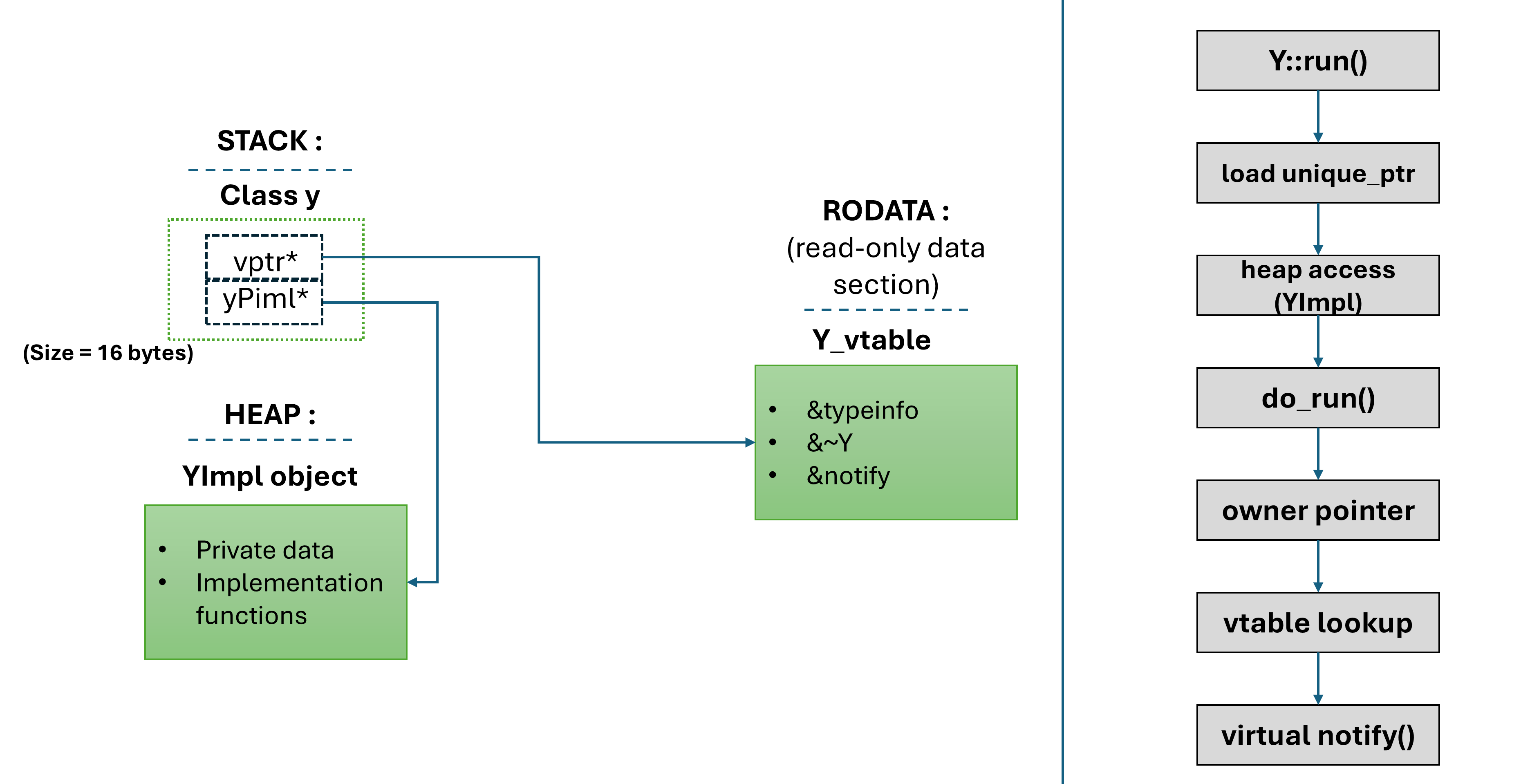
📌Note: During compile time, when the compiler detects a virtual function, it generates a vtable symbol and places it in the read-only data section. At runtime, there is only one vtable and all objects of the class point to it.
🔴The problem is evident: we are now chasing pointers🏃➡️. Rather than having contiguous memory and predictable access, we are now hopping between the stack and the heap and potentially missing cache lines.
Now we have two major problems at hand. First is now obvious that we have to deal with dynamic polymorphism, and the other one is that our PIMPL adaptation is not generic. Considering large frameworks with a lot of classes, imagine having to declare a pimpl pointer in every class with a forward declaration of the implementation entity. But how do we make this interface generic so that we don’t have to repeat the same code again and again?
Thankfully, C++ has a simple solution that helps us escape such problems: Templates (with some tweaks!).
One Step at a time!
Escaping Dynamic Polymorphism via CRTP
Polymorphism, derived from the Greek word polymorphos, is the ability to associate different specific behaviors with a single generic notation. However, when we talk about general polymorphism, it is almost always about run-time behavior detection, also known as dynamic polymorphism. A reason for it being, historically, C++ started with supporting polymorphism only through the use of inheritance combined with virtual functions. However, templates also allow us to associate different specific behaviors with a single generic notation, but this association is generally handled at compile time, which we refer to as static polymorphism (Vandevoorde et al., 2017, #). However, the approach using templates does not rely on the factoring of common behavior in base classes. Instead, templates provide us with different behaviors based on derived classes at compile time only. Since no indirection through pointers is needed a priori and nonvirtual functions can be inlined much more often, the generated code is much faster, but executable code size may be large. This approach is more type-safe since all the bindings are checked at compile time.
In simpler terms, rather than determining one specific behavior out of possible derived behaviors at run time and then generating code specific to it, we have all code templates of different behaviors based on derived classes at compile time only. However, this requires that the base class must be able to access the derived class. This is made possible by adapting the Curiously Recurring Template Pattern (CRTP) idiom introduced by James Coplien.
By passing the derived class down to its base class via a template parameter, the base class can customize its own behavior to the derived class without requiring the use of virtual functions. This makes CRTP useful to factor out implementations that can only be member functions (e.g., constructors, destructors, and subscript operators) or are dependent on the derived class’s identity.
Below is one possible adaptation of the CRTP idiom to make our solution detect polymorphic behavior at compile time:
#pragma once
#include <concepts>
#include <memory>
class D;
template <typename Derived>
class Y {
public:
explicit Y(const D &d);
~Y();
void someImpl();
void run();
protected:
void notify();
private:
struct YImpl;
std::unique_ptr<YImpl> yPimpl_;
};
#include "y.h"
#include "d.h"
#include <iostream>
template <typename Derived>
struct Y<Derived>::YImpl {
D d_;
YImpl(const D &d) : d_(d) {}
void do_run(Y *owner) {
owner->notify();
}
};
template <typename Derived>
Y<Derived>::Y(const D &d) : yPimpl_(std::make_unique<YImpl>(d)) {}
template <typename Derived>
Y<Derived>::~Y() = default;
template <typename Derived>
void Y<Derived>::run() {
yPimpl_->do_run(static_cast<Derived *>(this));
}
template <typename Derived>
void Y<Derived>::someImpl() {
std::cout << yPimpl_->d_.num << std::endl;
}
template <typename Derived>
void Y<Derived>::notify() {
static_cast<Derived *>(this)->notifyImpl();
}
#pragma once
#include "y.h"
#include <iostream>
class DerivedCL: public Y<DerivedCL> {
public:
using Y<DerivedCL>::Y;
void notifyImpl()
{
std::cout << "Derived notify\n";
}
};
🔔The intuition behind the code changes above is to avoid the usage of virtual functions to avoid dynamic polymorphism, yet preserve the benefits of the PIMPL idiom. However, there is one subtle and more important caveat here:
“Template code is generated only when a template is instantiated, and instantiation happens where the full definition is visible. Templates are compiled on demand, not beforehand.”
C++ compiles .cpp files independently, and linking is done at a later stage. Suppose a main.cpp is making use of our existing structure. It instantiates a derived class of Y, passes necessary parameters, and calls upon required member functions. But, the problem is that when it gets compiled, the compiler will see only:
template<typename T>
class Y;
The implementation details are present in y.cpp file and are not visible to main.cpp, as it has not been linked yet. We then have two options: either move definitions in the header or explicitly instantiate the template (least favorable). This is the core reason why C++ STL is header-only.
🔔 There is another problem with the code above: what if the derived class fails to implement the required function definition? How do we ensure that behavior exists to satisfy our structure?
Here is the more refined version:
#pragma once
#include <memory>
#include <iostream>
class D;
template <typename Derived>
class Y {
public:
explicit Y(const D& d);
~Y();
void run();
void someImpl();
protected:
void notify();
private:
struct YImpl;
std::unique_ptr<YImpl> yPimpl_;
};
#include "d.h"
template <typename Derived>
struct Y<Derived>::YImpl {
D d_;
explicit YImpl(const D& d)
: d_(d) {}
void do_run(Y* owner)
{
owner->notify();
}
};
template <typename Derived>
Y<Derived>::Y(const D& d)
: yPimpl_(std::make_unique<YImpl>(d))
{}
template <typename Derived>
Y<Derived>::~Y() = default;
template <typename Derived>
void Y<Derived>::run()
{
yPimpl_->do_run(this);
}
template <typename Derived>
void Y<Derived>::someImpl()
{
std::cout << yPimpl_->d_.num << std::endl;
}
template <typename Derived>
void Y<Derived>::notify()
{
static_assert(
requires(Derived d) { d.notifyImpl(); },
"Derived must implement: void notifyImpl();"
);
static_cast<Derived*>(this)->notifyImpl();
}
#pragma once
#include "y.h"
#include <iostream>
class DerivedCL : public Y<DerivedCL> {
public:
using Y<DerivedCL>::Y;
void notifyImpl()
{
std::cout << "Derived notify\n";
}
};
In the code presented above, template implementation details have been moved to the header only, and more importantly, the CRTP contract is being enforced by static_assert without any circular constraints. Everything is resolved at compile time without any need for a vtable pointer. However, a problem still lurks around: the owner must be manually passed everywhere {do_run(Y* owner)}. A good idea would be to make the YImpl owner aware.
#pragma once
#include <iostream>
#include <memory>
class D;
template <typename Derived> class Y {
public:
explicit Y(const D &d);
~Y();
void run();
void someImpl();
protected:
void notify();
private:
struct YImpl;
std::unique_ptr<YImpl> yPimpl_;
};
#include "d.h"
template <typename Derived> struct Y<Derived>::YImpl {
Derived &owner_;
D d_;
YImpl(Derived &owner, const D &d) : owner_(owner), d_(d) {}
void do_run() {
owner_.notifyImpl();
}
};
template <typename Derived>
Y<Derived>::Y(const D &d)
: yPimpl_(std::make_unique<YImpl>(static_cast<Derived &>(*this), d)) {}
template <typename Derived>
Y<Derived>::~Y() = default;
template <typename Derived>
void Y<Derived>::run() { yPimpl_->do_run(); }
template <typename Derived>
void Y<Derived>::someImpl() {
std::cout << yPimpl_->d_.num << std::endl;
}
template <typename Derived>
void Y<Derived>::notify() {
static_assert(
requires(Derived d) { d.notifyImpl(); },
"Derived must implement: void notifyImpl();");
static_cast<Derived *>(this)->notifyImpl();
}
However, to make the YImpl owner aware, we have introduced a problem. We introduced Derived& owner_; inside the implementation, which causes potential pitfalls when move semantics come to the picture. What happens when a piece of code tries to move the owner itself?
DerivedCL a(d);
DerivedCL b = std::move(a);
After the move semantics play, our implementation will be left with a null-pointer. Hence, a guarantee needs to be provided that once the owner is moved, the owner's reference is updated inside the implementation.
The constraint we have currently is that our implementation of the PIMPL idiom, YIMPL, remains unaware when a move happens. This event occurs outside its scope. Hence, it needs to be communicated once the owner detects a move operation. Moreover, there is one more subtlety we need to be aware of. We are storing the owner’s reference Derived& owner_; inside our implementation, and references cannot be rebound unless they are of type std::reference_wrapper<T>.
#pragma once
#include <iostream>
#include <memory>
class D;
struct impl_base {
virtual ~impl_base() = default;
virtual void set_owner(void *) {}
};
template <typename T> class impl_owner : public impl_base {
protected:
impl_owner(T &owner) : owner_(owner) {}
T &owner() { return owner_.get(); }
const T &owner() const { return owner_.get(); }
void set_owner(void *new_owner) override {
owner_ = *static_cast<T *>(new_owner);
}
private:
std::reference_wrapper<T> owner_;
};
template <typename Derived> class Y {
public:
explicit Y(const D &d);
~Y() = default;
Y(Y &&other) noexcept;
Y &operator=(Y &&other) noexcept;
void run();
void someImpl();
private:
struct YImpl;
std::unique_ptr<impl_base> impl_;
void rebind_owner();
};
#include "d.h"
template <typename Derived> struct Y<Derived>::YImpl : impl_owner<Derived> {
D d_;
YImpl(Derived &owner, const D &d) : impl_owner<Derived>(owner), d_(d) {}
void do_run() { this->owner().notifyImpl(); }
};
template <typename Derived> Y<Derived>::Y(const D &d) {
impl_ = std::make_unique<YImpl>(static_cast<Derived &>(*this), d);
}
template <typename Derived>
Y<Derived>::Y(Y &&other) noexcept : impl_(std::move(other.impl_)) {
rebind_owner();
}
template <typename Derived>
Y<Derived> &Y<Derived>::operator=(Y &&other) noexcept {
impl_ = std::move(other.impl_);
rebind_owner();
return *this;
}
template <typename Derived> void Y<Derived>::rebind_owner() {
if (impl_)
impl_->set_owner(static_cast<Derived *>(this));
}
template <typename Derived> void Y<Derived>::run() {
static_cast<YImpl *>(impl_.get())->do_run();
}
template <typename Derived> void Y<Derived>::someImpl() {
auto *impl = static_cast<YImpl *>(impl_.get());
std::cout << impl->d_.num << std::endl;
}
In the updated code above, we have introduced a communication channel to allow the owner to communicate lifecycle changes to the YImpl. The owner now no longer depends on the implementation layout. Rather than holding std::unique_ptr<YImpl>, the owner now holds std::unique_ptr<impl_base>.
An argument can be made that virtualization is back in our code, but this time we are not virtualizing behavior, but passing on a communication at run time, and this event is also not as frequent as it happens only when move semantics is at play.
In the updated code above, we have introduced a communication channel to allow the owner to communicate lifecycle changes to the YImpl. The owner now no longer depends on the implementation layout. Rather than holding std::unique_ptr<YImpl>, the owner now holds std::unique_ptr<impl_base>.
🎯Our final goal should be a reusable infrastructure where any class T automatically gets a PIMPL, and optionally allows the implementation to call back into its owner safely (even after move semantics).
👉Hence, the final leap, and we present you the Docwire adaptation of the PIMPL idiom.
The Final Leap: Docwire’s PIMPL adaptation
What we have developed so far is not a feature of a specific class, but an improved capability of a class. And this capability should be enabled for all other classes in the framework.
©️Following is the actual code in the Docwire framework for the PIMPL adaptation:
#ifndef DOCWIRE_PIMPL_H
#define DOCWIRE_PIMPL_H
#include <memory>
namespace docwire
{
template <typename T>
struct pimpl_impl;
class with_pimpl_base {};
struct pimpl_impl_base
{
virtual ~pimpl_impl_base() = default;
virtual void set_owner(with_pimpl_base&)
{
}
};
template <typename T>
class with_pimpl_owner;
template <typename T>
class with_pimpl : public with_pimpl_base
{
protected:
using impl_type = pimpl_impl<T>;
template <typename... Args>
impl_type* create_impl(Args&&... args)
{
if constexpr (std::is_base_of_v<with_pimpl_owner<T>, impl_type>)
{
static_assert(std::is_constructible_v<impl_type, T&, Args...>,
"Template specialization of pimpl_impl<T> that inherits from with_pimpl_owner<T> is required to have constructor with T&, Args... arguments");
return new impl_type(static_cast<T&>(*this), std::forward<Args>(args)...);
}
else
{
static_assert(std::is_constructible_v<impl_type, Args...>,
"Template specialization of pimpl_impl<T> is required to have a constructor with Args... arguments");
return new impl_type(std::forward<Args>(args)...);
}
}
template <typename... Args>
explicit with_pimpl(Args&&... args)
: m_impl(static_cast<pimpl_impl_base*>(create_impl(std::forward<Args>(args)...)))
{
}
with_pimpl(with_pimpl<T>&& other) noexcept
: m_impl(std::move(other.m_impl))
{
if (m_impl)
set_impl_owner();
}
with_pimpl(std::nullptr_t) {}
with_pimpl& operator=(with_pimpl&& other) noexcept {
if (this != &other)
{
m_impl = std::move(other.m_impl);
if (m_impl)
set_impl_owner();
}
return *this;
}
template <typename DeferInstantiation = void>
impl_type& impl() { return *static_cast<impl_type*>(m_impl.get()); }
template <typename DeferInstantiation = void>
const impl_type& impl() const { return *static_cast<impl_type*>(m_impl.get()); }
private:
std::unique_ptr<pimpl_impl_base> m_impl;
void set_impl_owner()
{
m_impl->set_owner(*this);
}
};
template <typename T>
class with_pimpl_owner : public pimpl_impl_base
{
protected:
with_pimpl_owner(T& owner) : m_owner(owner) {}
T& owner() { return m_owner; }
const T& owner() const { return m_owner; }
void set_owner(with_pimpl_base& owner) override
{
m_owner = static_cast<T&>(static_cast<with_pimpl<T>&>(owner));
}
private:
std::reference_wrapper<T> m_owner;
friend with_pimpl<T>;
};
}
#endif
We start with the intent of making PIMPL usable and introduce a specialization:
template<class T>
class with_pimpl;
---------------------------
template<typename T>
struct pimpl_impl;
We move the PIMPL implementation outside the class, and now the owner type decides implementation, and binding happens automatically. The class with_pimpl implements a generic, reusable PIMPL framework which aims to centralize ownership while maintaining owner reference, enforce correct construction rules, support move semantics safely, and hide implementation completely from headers. With the approach above, the following is achievable:
class parser : public with_pimpl<parser> {};
The derived class gains a full PIMPL system. The class with_pimpl comes with a construction engine, create_impl, which dynamically creates the implementation object and supports cases where the implementation needs an owner reference to call a public API.
using impl_type = pimpl_impl<T>;
This is the type definition that resolves the concrete implementation type and is returned by create_impl. However, when we store an implementation object inside the with_pimpl class, we store it via a base-class pointer: std::unique_ptr<pimpl_impl_base> m_impl; rather than pimpl_impl<T>. Had it been the latter case, then every translation unit, including the header, must always be aware of pimpl_impl<T>, which beats the purpose of the entire exercise. Any change in implementation would cause the whole code to compile. As a workaround, we define:
struct pimpl_impl_base
{
virtual ~pimpl_impl_base() = default;
virtual void set_owner(with_pimpl_base&)
{
}
};
And while instantiating the template through a class T in our .cpp file elsewhere, we write:
template<>
struct pimpl_impl<T> : pimpl_impl_base
{
...
};
As a result, an IS-A relationship is created between pimpl_impl<T> and pimpl_impl_base, since C++ supports Standard polymorphic upcast. And it also paves the way to store different concrete types behind one uniform interface.
🕵️There is a strange code, though:
template <typename DeferInstantiation = void> impl_type& impl();
C++ performs template instantiation whenever the compiler wants to check correctness, and in doing so, it may instantiate templates earlier than expected to verify validity.
The definitions of entities generated by a template are not limited to a single location in the source code. The location of the template, the location where the template is used, and the locations where the template arguments are defined all play a role in the meaning of the entity. When a C++ compiler encounters the use of a template specialization, it will create that specialization by substituting the required arguments for the template parameters. This implies that the compiler often needs access to the full definition of the template and some of its members at the point of use (Vandevoorde et al., 2017, #).
👀Look at the code above closely, especially the following segment:
template <typename T>
class with_pimpl
{
protected:
using impl_type = pimpl_impl<T>;
};
Here, pimpl_impl is only forward declared. The real implementation lives elsewhere. When the compiler is compiling the header, it will come across the following code segment:
impl_type& impl() { return *static_cast<impl_type*>(m_impl.get());
At this juncture, the compiler must verify the validity of the cast and dereferencing and check whether the return expression is well-formed or not. And to do this validation, it may need semantic information about pimpl_impl<T>. When the compiler encounters the inline definition of impl(), it may instantiate this member function while forming pimpl_impl<T>.
🔑Here, impl_type might be incomplete, since a complete definition of pimpl_impl<T> may not have been provided to the compiler yet. In such cases, operations such as casting and dereferencing can become ill-formed and break compilation.
In C++, templates follow Point-of-Instantiation rules, which direct a compiler to instantiate member functions as soon as the class template is instantiated, not when called. This is where ‘Deferred Instantiation’ comes to help. We convert a normal member function into a member function template, and in C++, Function templates are instantiated ONLY when used.
👉In short, the PIMPL idiom is a tradeoff between compile-time scalability and memory locality. For our use case, the Docwire being an SDK, we decided to weigh towards scalability. If it had been a performance-critical application, then memory locality would have been preferred. Having said that, this does not mean we do not care about performance! 😈
🔗Docwire Code Repo Link
References
Coplien, J. O. (1991). Advanced C++ Programming Styles and Idioms. Addison Wesley.
Sutter, H. (1999). Exceptional C++. Addison-Wesley.
Vandevoorde, D., Gregor, D., & Josuttis, N. M. (2017). C++ Templates: The Complete Guide (2nd ed.). Addison Wesley.
